
2022 has seen amazing progress in machine learning. Text-to-image models like Imagen and DALL-E 2 have reached impressive levels of realism and aesthetic quality, while large language models like ChatGPT display unnerving prowess in coding and written communication. The pace of progress is dizzying, and the potential effects on society are not yet clear.
One model in particular has captivated my attention since its August 2022 release, and more recently has provoked the ire of many: Stable Diffusion. This is a text-to-image model trained using the LAION-5B dataset, a collection of 5 billion images and text captions scraped from the Internet. Although these images are nominally public, a number of artists are outraged that their work has been fed into the machine without their knowledge or consent, seeing how elements cribbed from their oeuvres show up extensively in the outputs of the model.
It is wrong for others to profit from the infinite remixing of artists' labor without recompense. In a context where cultural production is already heavily commoditized, the threat of being automated out of a job is all too clear. However, this prospect isn't limited to the art world: ChatGPT can arguably write a college essay or pass a Google coding interview already, and could soon supplant many parts of my day-to-day work as a software engineer. In my estimation, these technologies and their successors stand poised to disrupt the entire landscape of knowledge work as it exists today, likely within just a few years.
I have no idea how we as a society will weather this phase shift, nor how the livelihoods of artists or anyone else can be protected under capitalism. However, amid the dire predictions, fury, and tumult, I wish to marvel at the mystery of what these tools are already able to do.
I believe that Stable Diffusion is doing something more interesting than regurgitating its training data. Without any world knowledge or conscious awareness, this model has encoded meaningful internal relationships within our visual and written languages, and without being "creative" in itself, is capable of combining elements at a conceptual level to create novel syntheses. Those familiar with Searle's "Chinese Room" argument may be amused to note that a purely mechanical "understanding" of the kind described therein apparently suffices to carry out many tasks we thought of as uniquely human.
Rather than rail against these remarkable developments, which will soon be at the disposal of anyone with enough computing power, I hope to understand them better and learn to ride the wave of what's coming. To that end, I'll try to describe informally how Stable Diffusion works and share my experience teaching it to generate portraits of me, my husband, and our cats.
- What is Stable Diffusion?
- Prompting
- Textual Inversion
- Composing the Shot
- Happy Holidays from Latent Space
- Parting Thoughts
What is Stable Diffusion?
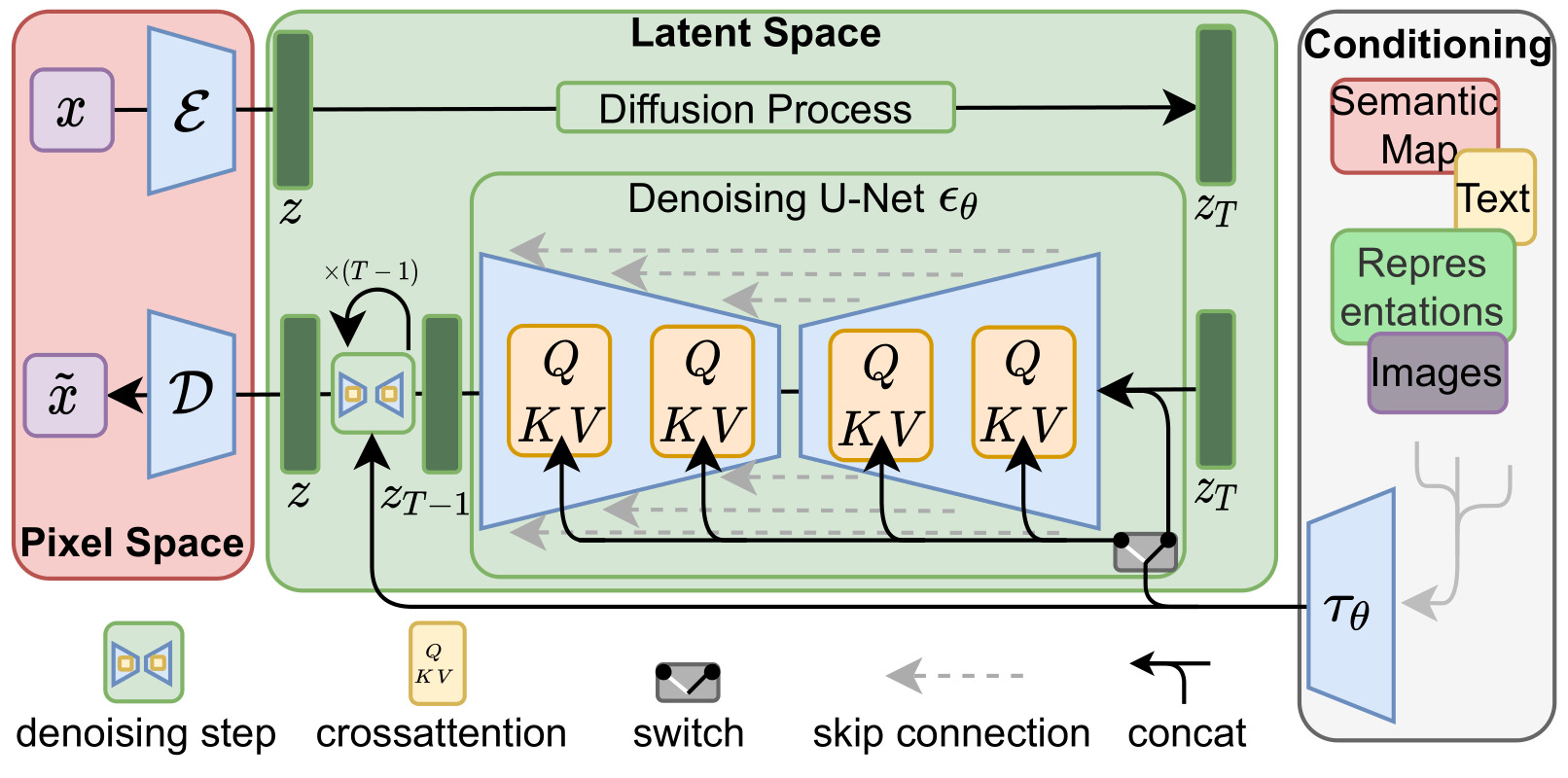
Stable Diffusion has a complicated architecture, but essentially consists of three parts: an autoencoder (left), a denoiser (center), and a conditioning mechanism (right). To understand what all this is doing, let's think step-by-step.
Autoencoder
The autoencoder is the simplest part: its purpose is to shrink a high-resolution image into a thumbnail, or expand a thumbnail into a full image. This reduces the complexity of the image generation task; turns out it's much easier to generate a small icon of the image you want and scale it up than to produce the whole thing at full size. (It also means that an 8-by-8 patch of pixels is shrunk down to a single pixel in the model's inner eye, which contributes to its struggles with fine details like hands.)
Denoiser

The denoiser is the core of the model, furnishing it with raw image generation capability. During training, it takes thumbnails from the autoencoder and adds noise (random pixels) to them until they are completely randomized, then teaches itself how to undo this process, guessing its way back from random noise to a (hopefully) coherent image.
This procedure is somewhat akin to imagining faces in the clouds, as the denoiser works to produce structure from nonsense by first interpreting what it "sees" in the noise and expanding on these interpretations. Importantly, it needs guidance on what to aim for, or the output will be a generic sample from the distribution of things it has seen before. These images often have a curiously vacant character, as if waiting to be animated by some intention.

|

|

|

|
| four images with empty prompts | |||
Conditioning (CLIP)

Finally, the conditioning mechanism contains the model's semantic knowledge and reasoning capabilities about text and images. For Stable Diffusion, this mechanism is called CLIP (Contrastive Language-Image Pre-training). It translates both images and texts into a common numerical representation, known as a "latent space," then learns to pair up each image with its correct caption within this realm.
CLIP steers the denoiser toward images that have certain elements in them, whether they be individual details (a person holding a white vase) or global characteristics (blurry, cheerful, painted, photographic). It can also steer the image away from undesired elements, known as classifier-free guidance or "negative prompting."
CLIP uses the so-called transformer architecture, built around the "attention" module which has been the backbone of many advances in ML over the last 5 years. Attention entails making connections between different parts of the input and modeling their relationships to each other. Self-attention, the ability of the transformer to attend to its own internal associations, lets it build up a rich latent space that is often difficult to understand for a human being.
It's hard to say exactly what kinds of reasoning a transformer is capable of, but a team from Microsoft Research has begun to shed light on this question through a simplified reasoning task called LEGO (Learning Equality and Group Operations). This task involves posing sequences of variables and operations like "a = +1; b = −a; e = +b; d = −f; c = +d; f = +e" that require a chain of logic to resolve, and asking the model to assign values to each variable. The authors found that the models developed mechanisms for "association (long-range identity matching) [and] manipulation (short-range operations)," which could also be identified in language models like BERT that had not specifically been trained on this task. The impressive performance of ChatGPT suggests that we still have yet to encounter the limits of what transformers can learn.
Taken as a whole, the autoencoder, denoiser, and CLIP conditioning of Stable Diffusion form a powerful image generation system that can flexibly perform many tasks. But how do you actually use it?
Prompting

Some have asserted that all one does to produce an image with these models is to type what you want into a web form. While Stable Diffusion is quite powerful, achieving a specific result is actually fairly difficult in my experience (note the absence of the mirror in the image above), contrary to the claims that there is nothing creative or skillful in AI art.
Prompting is the interactive process of working with the model to attain your goal (or an interesting diversion therefrom), often involving numerous generations and trial and error to make your intentions clear. Rather than a one-and-done procedure, it is a feedback loop in which you and the machine are exploring a space of possibility together.
One way to think about a prompt is as an address for a location within the model's imaginary. Not only the words you use, but their order and the relationships between them, will prime the model to look for certain patterns in the static. People may write prompts as complete sentences, comma-separated lists, or inscrutable strings of garbled half-words; the model will use whatever you give it and navigate to a particular point in its latent space.
Random Seeds
| 1887838105 | 4069519546 | 1826200903 | 3008594124 |
| birth of the universe from a random seed, primordial quantum foam | |||
Once an initial prompt is given, a "random seed" (read: number) provides the raw materials to be shaped into an image having those traits. This seed is aptly named, as it contains the germ of the patterns that the model will identify– think of the tiny imbalances in the distribution of matter and energy near the Big Bang that have evolved into our observable universe.
In the animations above, you can see the progress of the denoising process for four different random seeds, as they move from chaos to order. Typically, the overall composition is set after a brief period of experimentation, and then fine details are filled in.
It may be that a certain random seed doesn't have the right ingredients to produce everything that CLIP thinks you are asking for. In this case, you will only see certain parts of your prompt portrayed, or the model may interpret the prompt differently than you expect. Each image is a kind of balancing act between the denoiser's preference to produce images in a certain distribution and the conditioning mechanism's attempt to steer it toward your prompt, and it may have to give up on certain elements in order to keep the overall result reasonable.
If you find a seed with an interesting composition that doesn't quite have everything you want, you can reuse the seed while tweaking the prompt to obtain a different outcome. Here are three images using the seed 3754952516.



Textual Inversion
Textual inversion is a technique to create new words ("tokens") for use in your prompts, based on a set of images. With this, you can specify "a portrait of X" where X is your cat, for instance. This provides a lightweight way to augment a model with new concepts, and is far less expensive than retraining the model itself.
This procedure attempts to translate the essence of your images into the model's language, even though the model has never seen them before. Rather than using literal words, it works directly in latent space by creating a set of vectors initialized from a starting point (like the vectors for "person" or "cat") and optimizing them via gradient descent to reproduce the target images. One can think of this as searching through the model's inventory of existing concepts to pinpoint your location in its latent space.
Using the popular AUTOMATIC1111 Stable Diffusion interface on my desktop with an NVIDIA RTX 3050, I trained textual inversion tokens for myself, my husband Alex, and our cats Koko and Winnie, using roughly 50 images each. Each one took about 20000 steps (~5 hours) to converge to my liking, though your mileage may vary.

This image has some slight errors, but it is nonetheless a reasonable facsimile of me – of course, I cherry-picked it from among countless variants that look less like me or have stranger issues.

Even the "off" images, though, reveal that the textual inversion clearly holds some data about my likeness and can recreate it semi-reliably. The same is more or less true for the rest of the gang:



The key point is that Stable Diffusion did not have to "see" our photos directly in order to reproduce them – the new tokens don't change the underlying network or training data. Instead, the pretrained model has seen enough similar images that it can recreate us on the basis of what are effectively verbal descriptions, like the most precise sketch artist imaginable.
What's more, Stable Diffusion isn't limited to recreating the real photos that went into the textual inversion process. The resultant tokens hold an abstract notion of their subjects that can be placed into varying situations.



Although the tokens created by textual inversion can't be translated back into intelligible words, the process illustrates that Stable Diffusion's inner workings are more complicated and subtle than simply spitting back out what it was trained on. The model's latent space is sufficiently expressive that, given suitable direction, it is able to generate things it has never seen before.
At the same time, textual inversion is subject to limitations, as I will describe below.
Composing the Shot
Armed with four separate tokens for the members of my family, I attempted to put together an image with all four of us. Yet I found that I was unable to do so – when including the individual tokens in the same image, my husband and I would be rendered as a single person or fail to appear altogether. Similarly, invoking both cats would only result in one.


However, pairing one person with one cat had more success:


I suspect this is because the textual inversions for two humans (or two cats) are harder to separate from each other, as they are describing members of the same class. CLIP doesn't really have a notion of discrete objects or spatial relationships, so tokens intended to affect separate parts of the image may well be applied mistakenly to the same region, especially if they are similar in nature.
To overcome this problem, I created two new tokens: one with photos of me and Alex together ("coralex"), and one with Winnie and Koko together ("winnieko"). Using these, the model was more readily able to produce images of the human and cat pairs, albeit frequently requiring additional prompting to generate both cats– probably because the cats don't hang out much in real life, so the training data was lacking.


Finally, using these two pair tokens, I was able to produce images with the four of us, or at least some fun imitations thereof.
Happy Holidays from Latent Space




Parting Thoughts

As of this writing, an MIT Technology Review article notes that Stability.AI will allow artists to opt out of the training data for the next version of Stable Diffusion. The legal and sociotechnical issues raised by these models are far from being settled, and some may say that letting people opt out isn't going far enough.
I think Pandora's box is already open– even if Stability never trains another model, the wider world will have access to this and similar capabilities from now on. The question is how we will respond to it, and how to instill human values into the making of these technologies at every level.
For my part, I'm excited by the potential of these models, have had a lot of fun interacting with them, and am frightened by how the world may change in their wake. Despite the uncertainty ahead, I hope that the above foray into latent space can give a sense of what is so remarkable about these tools, and invite you to consider what kind of future you want to imagine.